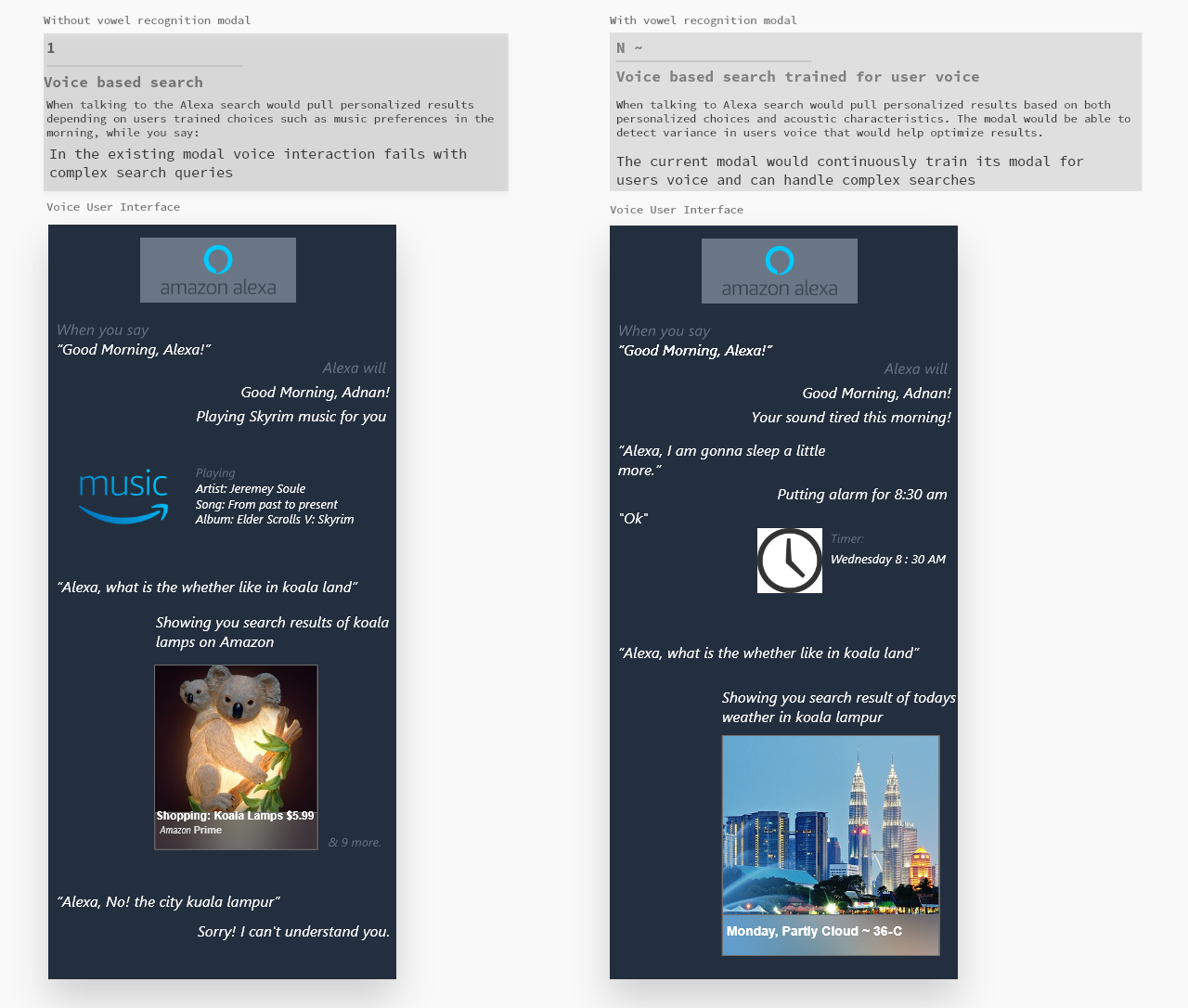
The problem
People with accents usually have a difficult time with their AI assistants. International community faces this problem often but even the regional lilts, dialects and drawls native to various parts of the United States also suffer to convey the right message. To them the artificial intelligent speakers can seem very different: inattentive, unresponsive, even isolating. For many technology users across countries, the wave of the future has a bias problem and it’s leaving them behind.
We are in the middle of a voice revolution. Voice-based wearables, audio, and video entertainment systems are already here. Due in part to distracted drivers, voice control systems will soon be the norm in vehicles.
Technology is shifting to respond to our vocal chords, but what will happen to the huge swath of people who can’t be understood?
My role & process
I was a research assistant in the perception lab where I conducted most of the research on multilingual subjects. In the longitudinal study, there were 17 non-native speakers and 5 native speakers of the English language. I developed the neural network which characterized the speech based on the vowel difference of participants. Based on the discovered features later I designed these interactions in the current voice-based systems (Amazon Alexa).
Kicking it Off
People with non-standard accents are more likely to encounter difficulties communicating when interacting with their AI assistants to avoid these they tend to alter the way they speak in order to be understood by voice assistants, such as Alexa (Amazon), Google Assistant, Siri (Apple) and Cortana (Microsoft).
Hey, Google. Do you prefer to speak with a particular accent?
I’m afraid you’ll have to put up with this one for now.
These voice-based systems are trained on the data set of English native speakers of American dialects and the voice-based systems is confused when processing various phonetic sounds of non-native speakers as it might get problems in achieving the set goal.
Hey, Google. Do you like the way I speak?
Sorry, I can’t judge. But I can play you some music.
Among the all phonetic sounds vowels are very important to any language; different languages have different vowel sounds in their speech (American English has 12 vowel sounds). Most of the voice-based synthesizers are developed primarily for American audience.
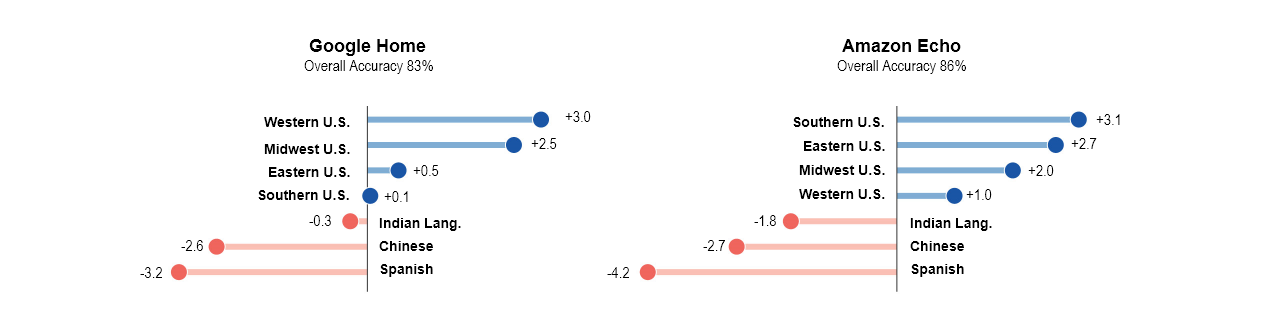
Study conducted by Rachel Tatman at university of Washington and popularized by the famous comedy sketch show, Burnistoun showcases the problem with the Intelligent speakers.
Research & Findings
In my study I focused bilingual users from big populations like India (11 vowel sounds) and China (9 vowel sounds) who has English as their second or third language. Participants produced English vowel sounds for 3 times in a long study with a month apart for three months.
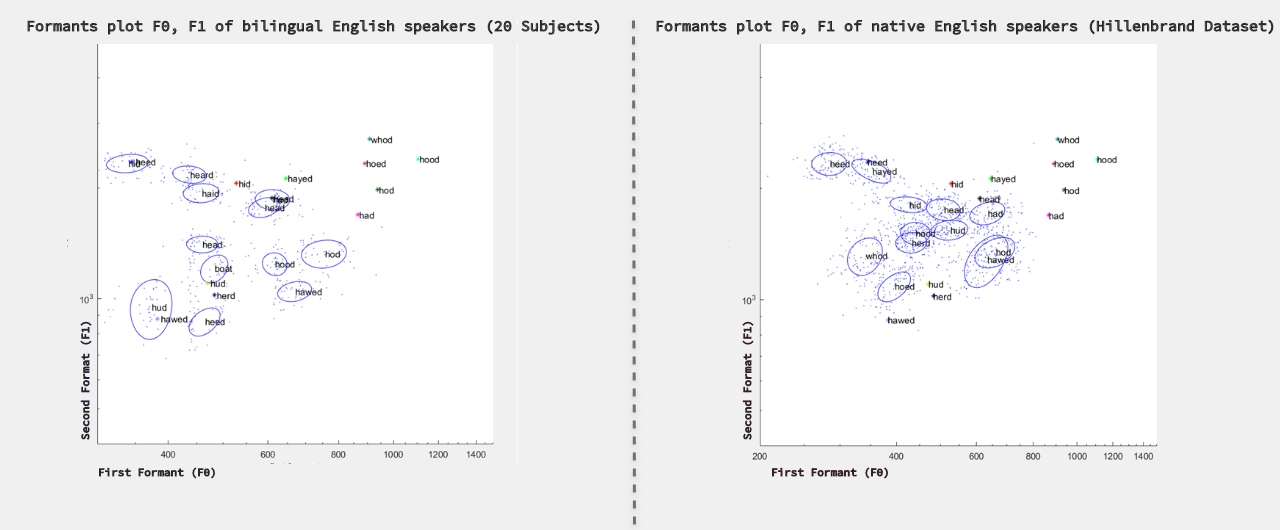
Participants produced these vowel sounds differently than English native speakers, they replaced English vowel sounds with the vowels from their primary language (mother tongues). The produced speech had some differences and the perception of these differences in their speech production was a critical factor in why people who have English as second or third language has a peculiar accent. To find the acoustics difference I compared the bilingual’s vowel formant frequencies (spectral shaping that results from an acoustic resonance of the human vocal tract) with the native English speaker’s vowel data bases. I used Hillenbrand’s Dataset and Assman & Kats Dataset bot contain formant frequency data of American dialects.
For the comparison I averaged the acoustic values of native speakers (made a white noise with Hillenbrand and Assman – Katz Datasets) and ran my participants data over the average acoustic value to find the extremes and similarities between speeches.
The study was designed to observe perception of speech but in daily life humans don’t just get pure speech from the sound source. There will always be noise involved so to study vowels perception and observe the effects of noise I added three different signal-to-noise ratio (SNR) values in the recorded speech. Vowels were analyzed at three different SNR values (-6dB, 0dB, +6dB). Acoustic characteristics of bilingual subjects than tested against the average acoustic characteristics of the native speakers. This process is repeated to calculate the standard error to create a predictive function. All the analysis was done in python.
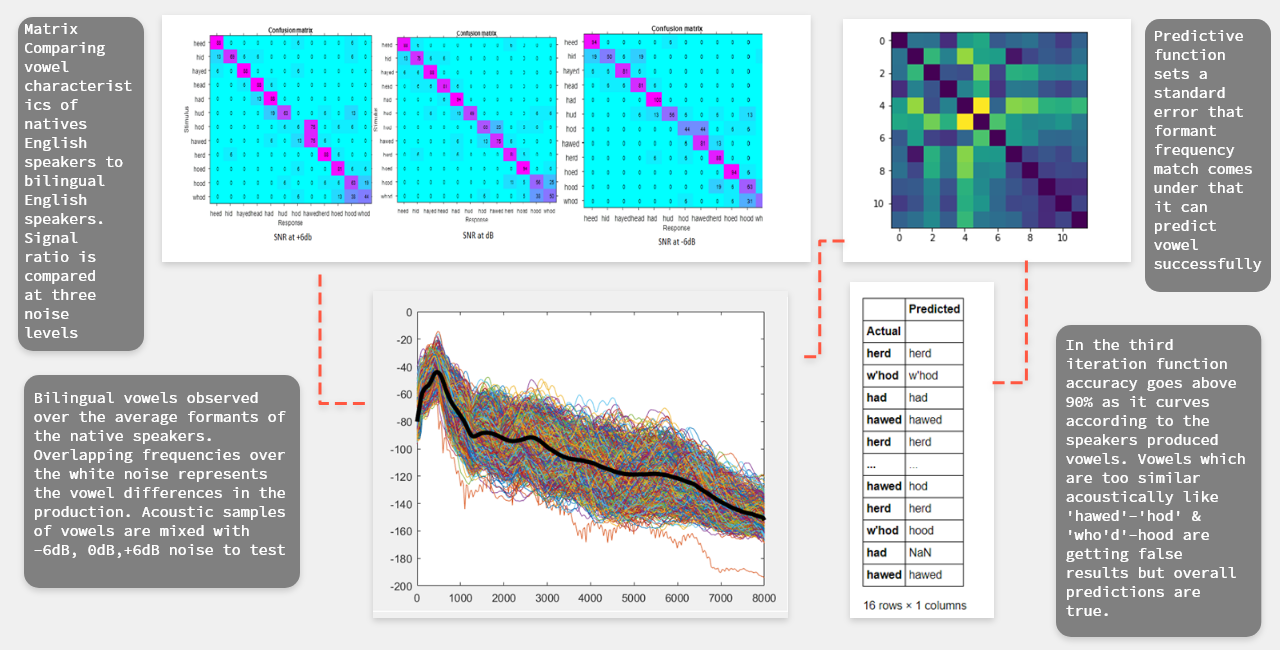
Making Sense of Data
In the calculated confusion matrix individual talkers (bilingual speakers) showed least relative values at diagonal so it confirmed there is not a huge amount of difference in acoustics.
The classifier calculated the standard error to predict the pronounced vowels against the native speakers with input from users with accent it gave the accuracy of 87%. Which is not that bad when looked in the context of performing daily instruction but can’t handle complex & similar sounding commands.
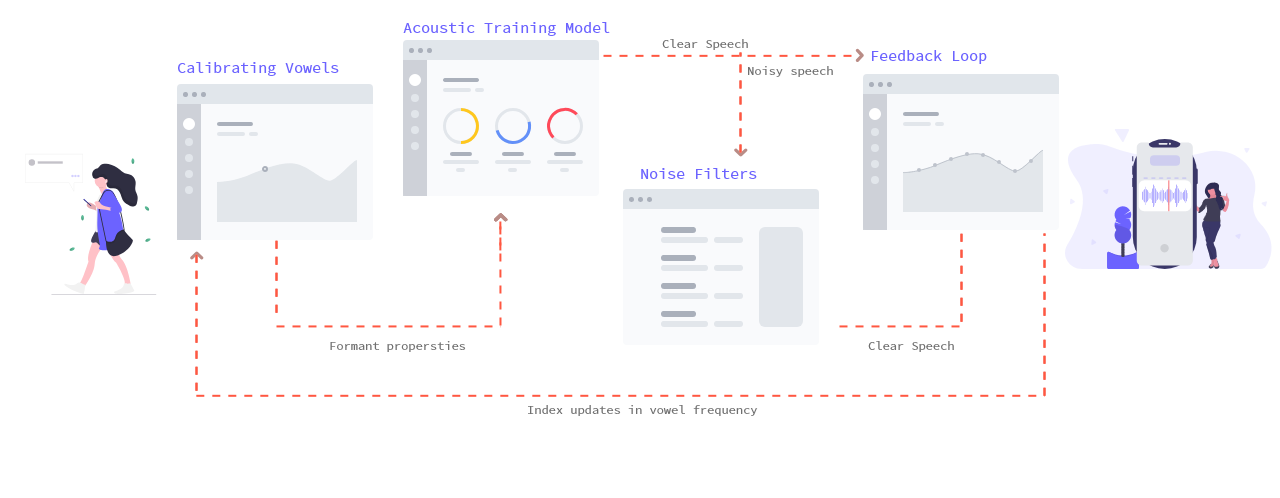
The predictive analysis was correctly recognized most of the vowels but failed when input vowels (bilingual speech) standard error was too similar with other vowel sounds. In case of the vowel ‘awe’ and ‘o’ the synthesizer failed to predict and also with vowel ‘ho’ the synthesizer predicted ‘oo’. Synthesizer was worst in predicting the vowel ‘ha’ it all altogether failed.
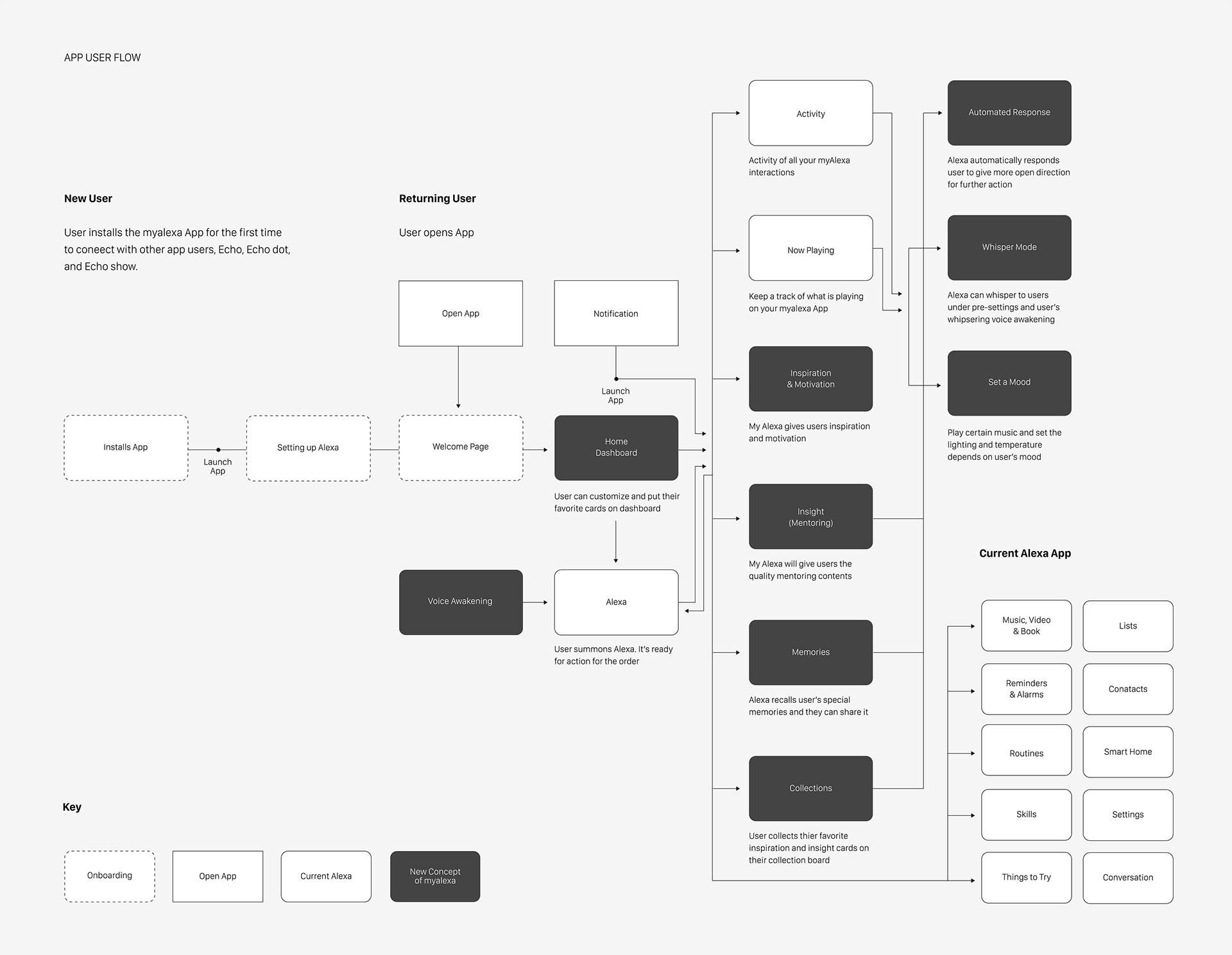
I came up with User flows with a focus on the experience and needs of the user not the small design details on the screens. A flow presents an overall picture and allows creating a more seamless user experience. Some flow highlights are entries and exits, how the system acts and its connection with the user's interactions. The flow also shows the number of decision points, which is where the user needs to do an active choice. Design the experience, not the looks.
Design & Evaluation
This study shows how geography effect vowel production in native speakers as well as bilinguals. The vowels which are similar between bilinguals and native speakers showed little variation.
Vowels [I], [E] and [AE] are closely coupled than other vowels and also these vowels are common to the speakers. These differences do not affect human’s perceptive ability to recognize the sounds, but digital synthesizers can’t.
This shows the present error that listeners can tolerate the perceived sound but smart speakers modal for recognition aren’t modeled to handle the vowel differences.
Some random values in confusion matric can be explained by vividness of the data used for the listener and digital synths. Low frequency noise did not affect perception that much when compared to high frequency noise.